
Meta has announced its latest state of the art open-source AI model – Llama 3. Llama 3 brings substantial improvements across various benchmarks, demonstrating substantial improvements over their predecessor, Llama 2. Llama being one of the leading open-source AI models, Llama3 launch was eagerly awaited by the open-source AI community.
Meta has currently made available 2 versions 8b and 70b with other versions coming later.
Key Highlights of Llama 3
- Debut with 2 versions: 8B parameters and 70B parameters with 8k context
- State-of-the-Art Performance: The new Llama 3 models significantly outperform previous iterations with enhanced reasoning, code generation, and instruction-following capabilities, thanks to improved pretraining and fine-tuning methodologies.
- Multimodel, Longer context and better multilingual performance – Llama 3 will have multimodel capable versions, it will also be releasing versions with long context windows. Plus the with 5% training data in languages other than English. Llama 3 will have improved multilingual performance across the board.
- Expanded availability: Llama 3 will be widely available across major platforms such as AWS, Google Cloud, and Microsoft Azure, and supported by leading hardware from AMD (Yes, AMD) to NVIDIA.
- Advanced Safety Tools: Meta introduces Llama Guard 2 and Code Shield to ensure safer deployments, along with comprehensive trust and safety resources for developers.
Performance of Llama 3: improvements across the board
Llama 3 has performance improvements in all the departments like reasoning, code generation, and instruction following. Meta states that its newly launched Llama 3 8B and 70B parameter scale models are the best in their class in the world currently. Meta credits the improvements made in pretraining and post-training for this.
If we look at Instruct model benchmarks of Llama 3 – it shows great performance and beats all the nearby competitors.
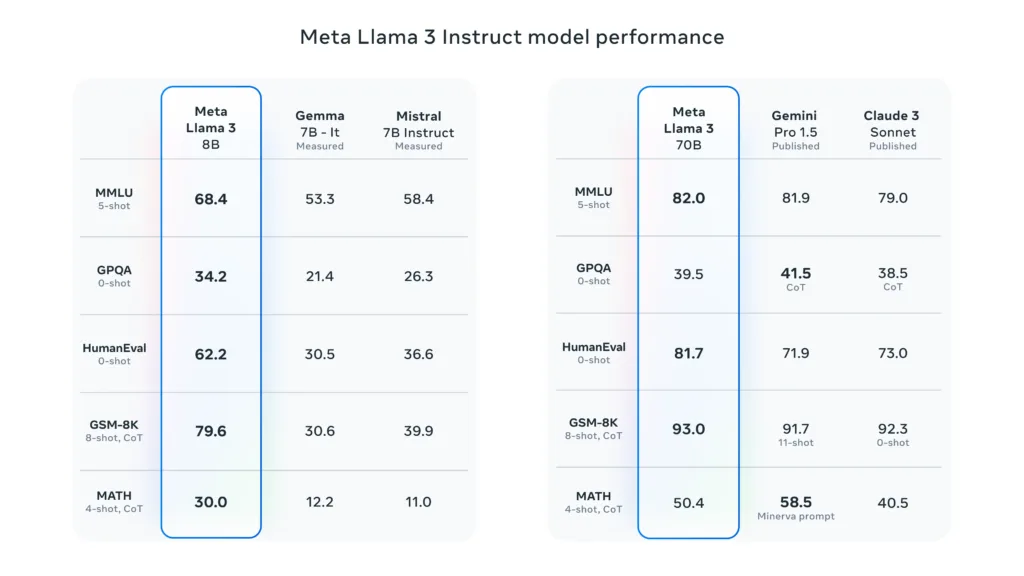
Meta said Llama shows great performance even in real-world scenarios and not just benchmarks. To quantify this, Meta has developed a new high-quality human evaluation set. According to Meta “This evaluation set contains 1,800 prompts that cover 12 key use cases: asking for advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization.”

Meta also emphasises on the Llama 3 Pretrained model performance – which, according to them, also establishes a new state-of-the-art for LLM models at those scales.

Architecture of Llama 3
In terms of architecture, Llama 3 employs a decoder-only transformer architecture, which is the same as last year’s Llama 2. But the Llama 3 employs a tokenizer of 128K tokens, double that of Llama 2, which ensures superior performance. The models are pretrained on a dataset more than seven times larger than its predecessor, featuring an extensive range of high-quality, diverse data.
Training and Fine-Tuning: A Peek Behind the Curtain
The training of Llama 3 models has been scaled up significantly to utilize up to 15 trillion tokens and leverage advanced parallelization techniques. For reference, Llama 2 was trained on 2 trillion tokens. This robust training regimen has resulted in models that continue to improve performance, even beyond the datasets used during their initial training phase.
To quote Andrej Karpathy on this, – “15T is a very very large dataset to train with for a model as “small” as 8B parameters, and this is not normally done and is new and very welcome. The Chinchilla “compute optimal” point for an 8B model would be train it for ~200B tokens. (if you were only interested in getting the most “bang-for-the-buck” w.r.t. model performance at that size). So this is training ~75X beyond that point, which is unusual but personally, I think extremely welcome.
Because we all get a very capable model that is tiny, easy to work with and inference. Meta mentions that even at this point, the model doesn’t seem to be “converging” in a standard sense. In other words, the LLMs we work with all the time are significantly under-trained by a factor of maybe 100-1000X or more, nowhere near their point of convergence. Actually, I really hope people carry forward the trend and start training and releasing even more long-trained, even smaller models.”
Training on more tokens is all you need
The training data of Llama 3 has better training data as well, with a lot of attention to quality, 4X more code tokens, and 5% non-en tokens over 30 languages. For languages other than English, 5% data is still low, but still better and will give improved multilingual performance to Llama 3. But overall, the model is English first only.
Fine-tuning
Fine-tuning these models involved a combination of supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct policy optimization (DPO). The quality of the prompts that are used in SFT and the preference rankings that are used in PPO and DPO has an outsized influence on the performance of aligned models.
Safe and Responsible Deployment
Meta has taken a system-level approach to ensure the responsible deployment of Llama 3 models. This includes comprehensive safety testing and the development of new safety tools and frameworks to mitigate risks associated with AI deployment.
The Llama Guard 2 and CyberSec Eval 2, along with the new Code Shield, are designed to enhance the security and integrity of AI applications, providing developers with the necessary tools to deploy AI safely and effectively.
Upcoming Llama 3 models – Longer context, Multimodel, 400B+
Meta plans to introduce even more sophisticated models, including a 400B parameter version of Llama 3. These developments are anticipated to further enhance the capabilities of AI applications and drive significant progress in the technology’s adoption and impact.

Meta Llama 3 availability
You can visit the Llama 3 website to download the models and reference the Getting Started Guide for the latest list of all available platforms.
You’ll also soon be able to test multimodal Meta AI on the Ray-Ban Meta smart glasses.
Leave a Reply
You must be logged in to post a comment.