
Meta has recently pulled back the curtain on its long-awaited SOTA Llama 3.1 405B Llm model. Along with this, Meta also launched updated Llama-3.1-70B & Llama-3.1-8B model.
With massive 128K token context window which can be helpful for long-form analysis, complex coding tasks, etc. Meta also significantly beefed up its multilingual capabilities, with support for English, French, German, Hindi, Italian, Portuguese, Spanish, and Thai.
It was just this April when Meta launched Llama 3 with 8B and 70B parameter models, hinting at a 405B powerhouse in development. Now, mere months later, we’re not only seeing the 405B model materialize but also witnessing significant upgrades to the 8B and 70B models, now branded as Llama 3.1.
This breakneck pace of innovation in genAI landscape is unprecedented. In just a few months, we’ve seen Google’s its nest iteration of its open weight AI model, Gemma 2, that’s been turning heads with its impressive performance metrics. Then, OpenAI introduced GPT-4o mini, a more streamlined and cost-effective variant of its renowned model.
However, Meta’s latest Llama 3.1 405B release stands out as a potential game-changer. It’s not merely keeping up with closed-source models; it’s challenging their supremacy. For advocates of open-source AI, this release represents a significant milestone. It shifts the narrative from whether open-source can match proprietary models to how quickly it might outpace them.
Llama 3 405B: The New Open Source Heavyweight
With 405 billion parameters, this model isn’t just big – it’s “BIG”. But in the world of large language models, size isn’t everything. It’s how you use those parameters that count.
In benchmark after benchmark, Llama 3.1-405B is going toe-to-toe with the likes of GPT-4 and Claude 3.5 Sonnet.
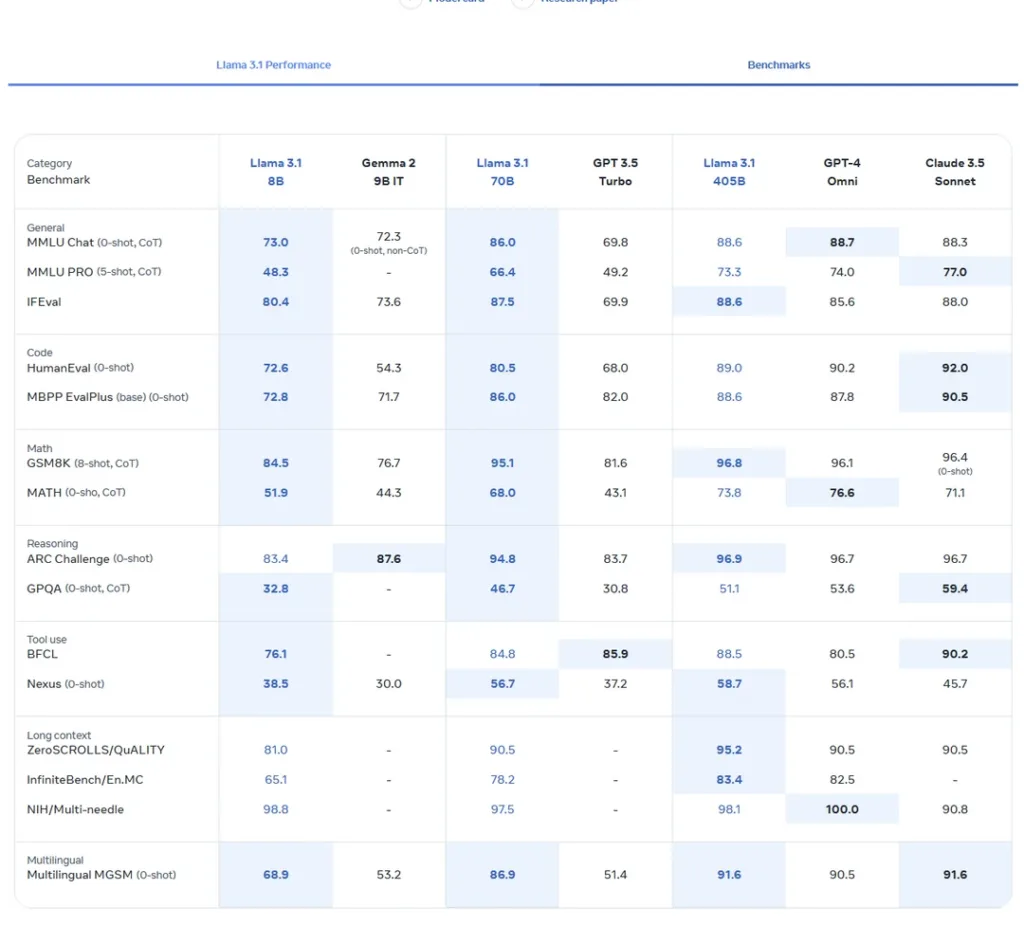
Meta’s benchmarks provide a compelling case for Llama 3 405B’s capabilities. Let’s break down some key performance metrics:
- General Language Understanding: In the MMLU Chat benchmark, Llama 3 405B scores 88.6, slightly edging out GPT-4 (88.7) and Claude 3.5 Sonnet (88.3).
- Code Generation: On HumanEval, Llama 3 405B achieves 89.0, competitive with GPT-4 (90.2) and not far behind Claude 3.5 Sonnet (92.0).
- Mathematical Reasoning: In the GSM8K benchmark, Llama 3 405B scores an impressive 96.8, surpassing both GPT-4 (96.1) and Claude 3.5 Sonnet (96.4).
- Reasoning: On the ARC Challenge, Llama 3 405B scores 96.9, slightly outperforming both GPT-4 and Claude 3.5 Sonnet (both at 96.7).
- Multilingual Capabilities: In the Multilingual MGSM benchmark, Llama 3 405B achieves 91.6, matching Claude 3.5 Sonnet and outperforming GPT-4 (90.5).
These benchmarks suggest that Llama 3 405B is not just keeping pace with closed-source giants – it’s giving them a run for their money. In several key areas, it’s matching or even slightly surpassing the performance of GPT-4 and Claude 3.5 Sonnet.
What’s particularly impressive is the leap in performance from previous Llama versions. Comparing Llama 3 405B to the April release of Llama 3 70B, we see significant improvements across all benchmarks. For instance, in the MMLU benchmark, we see a jump from 80.9 to 88.6, and in HumanEval, an increase from 81.7 to 89.0.
The implications of having a model of this caliber available openly are profound. It could accelerate research, enable smaller companies to compete with tech giants, and potentially lead to more transparent and accountable AI systems. However, it also raises questions about responsible AI deployment and the potential for misuse – issues that the AI community will need to grapple with as these powerful models become more accessible.
Upgrades to Llama 3.1 8B and 70B: Punching Above Their Weight
While the 405B model is grabbing headlines, the improvements to the 8B and 70B models shouldn’t be overlooked. These “lighter” versions have received significant upgrades, making them more versatile and powerful than ever before.
Let’s break down the key enhancements:
- Extended Context Window: Both models now boast a 128K context length, a dramatic increase from the previous 8K. This means they can process and understand much longer pieces of text, opening up new possibilities for document analysis, long-form content generation, and complex reasoning tasks.
- Improved Multilingual Support: The benchmarks show impressive gains in multilingual capabilities. For instance, the 70B model scores 86.9 on the Multilingual MGSM test, a significant improvement over its predecessor.
- Enhanced Reasoning Capabilities: The ARC Challenge scores demonstrate a notable jump in reasoning abilities. The 70B model now scores 94.8, up from 94.4 in the April release.
- Coding Prowess: On the HumanEval benchmark, the 70B model has improved from 81.7 to 80.5, while the 8B model jumped from 60.4 to 72.6, showing substantial gains in code generation and understanding.
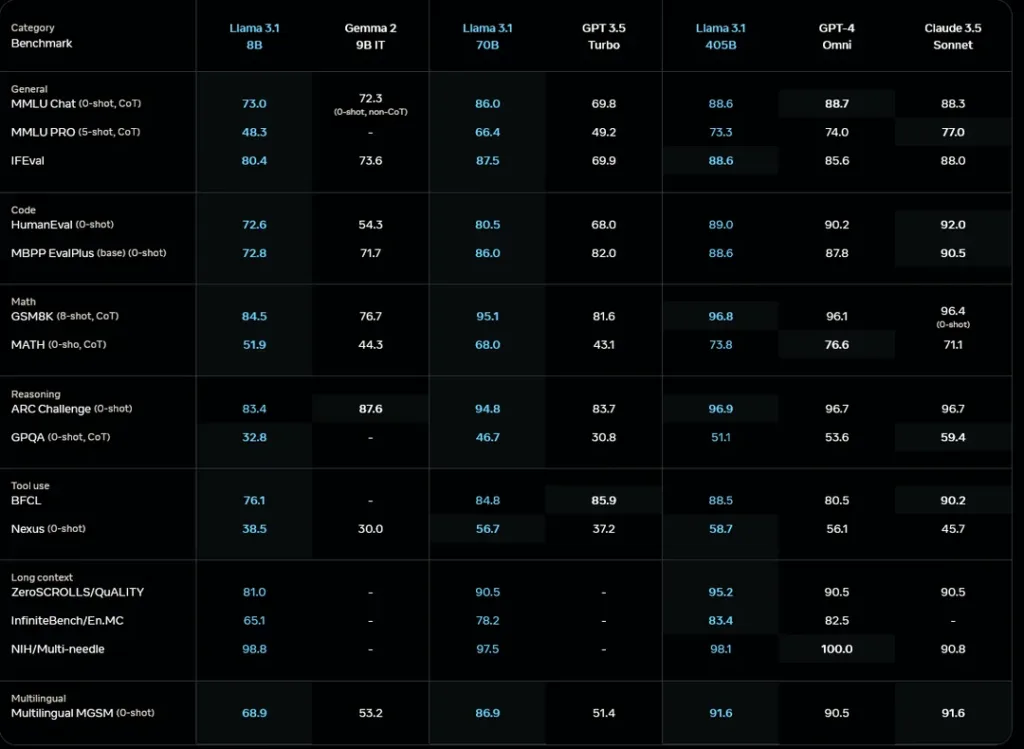
The 70B model, in particular, is now nipping at the heels of its larger 405B sibling in several benchmarks. This is crucial because while the 405B model might be the showstopper, it’s the more manageable 8B and 70B models that many developers and smaller organizations will likely use in practice due to their lower computational requirements.
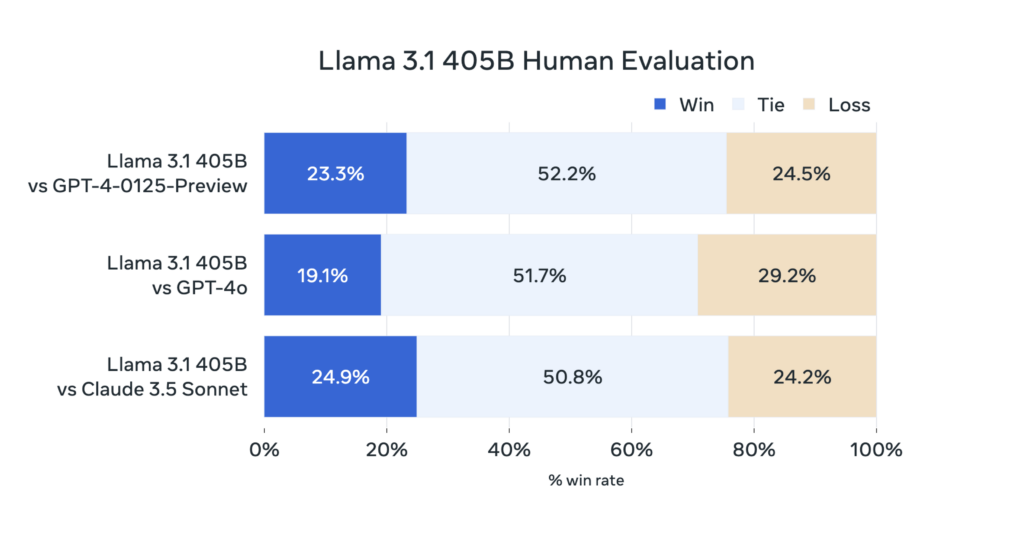
The Human benchmark by Meta also showcases the real world improvements in the models.
What’s particularly interesting is how these models stack up against competitors. The Llama 3.1 70B model outperforms GPT-3.5 Turbo across nearly all benchmarks, often by a significant margin. It’s even competitive with some aspects of GPT-4 and Claude 3.5 Sonnet, which is remarkable given its smaller size.
The advancements in these “smaller” models highlight an important trend in AI development – it’s not just about creating bigger models, but about making existing architectures more efficient and capable. This approach democratizes access to advanced AI capabilities, allowing a broader range of users to leverage state-of-the-art language models without requiring massive computational resources.
New Tools and Ecosystem: Building a Robust AI Infrastructure
Meta has also updated the accompanying tool like Llama Guard and Prompt guard.

Llama Guard 3: Fortifying AI Safety
As shown in the model selection image, Llama Guard 3 is a crucial addition to the Llama family. This “high-performance input and output moderation model” is designed to act as a safeguard for content generated by or fed into Llama models. It’s based on ML Commons safety categories, providing a standardized approach to content moderation. This is a critical tool for developers looking to deploy Llama models responsibly, helping to filter out potentially harmful or inappropriate content.
Prompt Guard: Defending Against Prompt Injection
Another new addition is Prompt Guard, described as a “powerful tool to safeguard against malicious prompt attacks.” This tool is specifically designed to protect against prompt injections and jailbreaks – techniques that malicious actors might use to bypass an AI model’s safeguards or manipulate its outputs. With Prompt Guard, developers can add an extra layer of security to their AI applications, ensuring more reliable and safer interactions.
The Llama Stack API: Standardizing AI Development
Meta has also put forth a proposal for the Llama Stack API, a standardized interface for AI development. This initiative aims to create a common ground for various AI tools and components to work together seamlessly. By standardizing interfaces for tasks like fine-tuning, synthetic data generation, and agentic applications, Meta hopes to foster greater interoperability within the AI ecosystem. This could significantly reduce development time and improve collaboration across different AI projects.
Expanding Partner Ecosystem
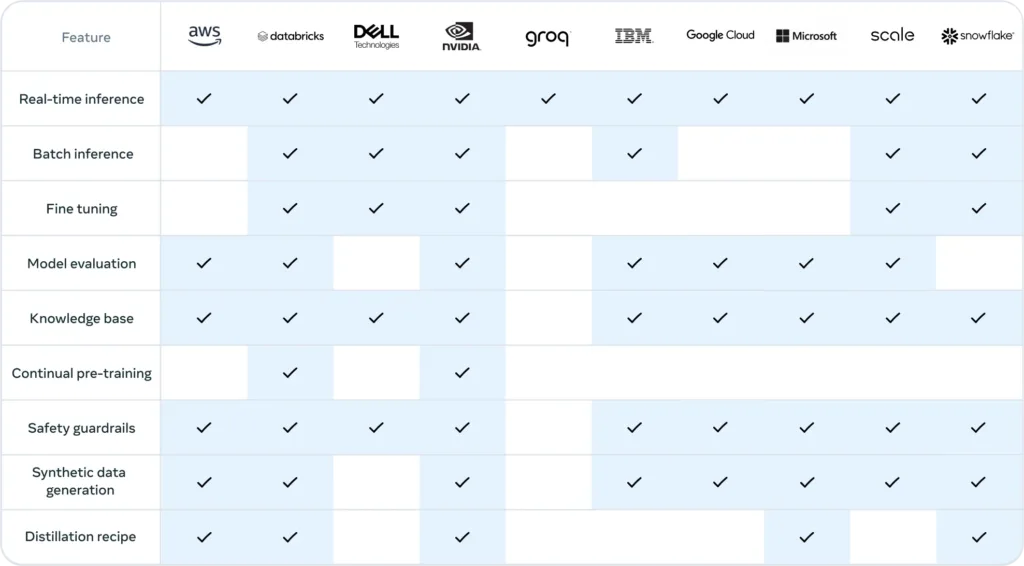
Meta has announced partnerships with over 25 major tech players, including AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud, and Snowflake. These partnerships are crucial for several reasons:
This robust ecosystem approach is a strategic move by Meta. By providing not just the models, but also the tools for responsible deployment and a standardized development framework, they’re positioning Llama as more than just a model – it’s becoming a comprehensive AI development platform.
Technology, Architecture, and Challenges
The development of Llama 3 405B represents a significant leap in open-source AI technology.
Model Architecture
Llama 3.1 405B uses a standard decoder-only transformer architecture same as in llama 3, first introduced in llama 2 models but with some key optimizations:
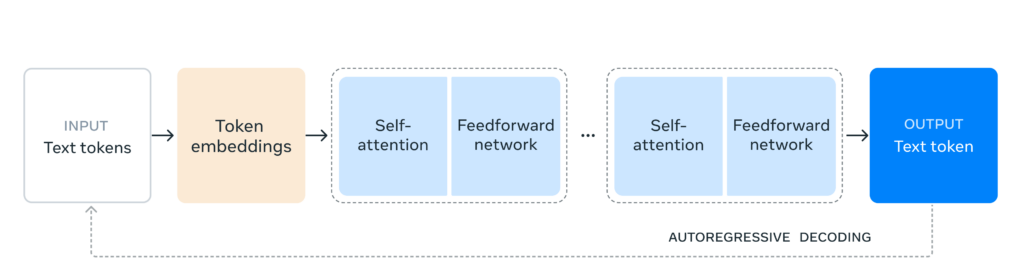
- Scaling Up: The jump to 405 billion parameters is a massive increase from previous Llama models. This scaling up allows for more nuanced understanding and generation of language.
- Context Length: The extended context window of 128K tokens is a significant architectural improvement, allowing the model to process and understand much longer pieces of text.
- Multilingual Support: The architecture has been optimized to handle multiple languages effectively, as evidenced by its strong performance on multilingual benchmarks.
Training Process
Training Llama 3 405B required over 15 trillion tokens and utilized more than 16,000 H100 GPUs. This level of computational power is staggering and highlights the resources needed for cutting-edge AI development.
Iterative Post-Training: Meta adopted an iterative post-training procedure, using supervised fine-tuning and direct preference optimization. This approach allowed for continuous improvement of the model’s capabilities.
Data Quality: Significant effort was put into improving both the quantity and quality of training data, with careful pre-processing and curation pipelines.
Technical Challenges
Developing and deploying a model of this scale comes with significant challenges:
- Computational Requirements: The sheer size of the 405B model makes it challenging to run on standard hardware. Meta has addressed this partly through quantization, reducing the model from 16-bit to 8-bit numerics to lower compute requirements.
- Inference Optimization: Running inference on such a large model in real-time is computationally intensive. Partners like Groq are working on optimized low-latency inference for cloud deployments, while Dell is focusing on on-premises solutions.
- Fine-Tuning Complexity: The size of the model makes fine-tuning for specific tasks more complex and resource-intensive.
Innovations and Solutions
To address these challenges, Meta and the AI community are innovating in several areas:
- Model Distillation: This technique allows for the creation of smaller, more efficient models that capture much of the knowledge of the larger 405B model.
- Synthetic Data Generation: Llama 3 405B’s capabilities in generating high-quality synthetic data could revolutionize the training of smaller, more specialized models.
- Safety Tools: The introduction of Llama Guard 3 and Prompt Guard demonstrates Meta’s commitment to addressing ethical concerns and promoting responsible AI use.
- Ecosystem Approach: By fostering a broad ecosystem of partners and developers, Meta is distributing the challenge of optimization and deployment across the industry.
There are further details on the optimisations and techniques in the llama 3.1 technical paper.
As the community continues to work with these models, we can expect further optimizations and innovations that will make powerful AI more accessible and manageable for a wider range of users and applications.
Accessing Llama Models: Availability of llama 3.1 405B, 70B and 8B
With the release of Llama 3 405B and the updated Llama 3.1 models, there’s understandably a lot of excitement about getting hands-on with these powerful AI tools.
General Access Options : How to use Llama 3.1 as general user
- WhatsApp Integration: In a move that brings advanced AI to a widely used messaging platform, Meta has made Llama 3.1 405B accessible via WhatsApp in the United States. This integration allows users to interact with the model by asking challenging math or coding questions directly within the chat interface.
- Meta AI Website: For those preferring a web-based interface, Meta has made the model available at Meta.ai. This platform likely offers a more comprehensive interaction experience, potentially allowing for longer conversations and more diverse query types.
- Hugging Chat: The AI community favorite, Hugging Face, has also integrated Llama models into their Hugging Chat interface. This provides another avenue for developers and AI enthusiasts to experiment with the models in a user-friendly environment.
Developer Access
For developers looking to integrate Llama models into their projects or conduct more in-depth research:
- Model Downloads: The model weights for Llama 3.1 (including 8B, 70B, and 405B versions) are available for download from Meta’s official Llama page – llama.meta.com and Hugging Face. Allowing for local deployment and customization.
- Partner Platforms: Meta’s partnerships with cloud providers like AWS, Google Cloud, and Azure, as well as ultra low-latency cloud providers like groq along with AI-focused companies like NVIDIA and Databricks, offer various deployment options for developers looking to scale their Llama-based applications.
EU Unavailability: At present, Llama models are not available in the European Union. This limitation is likely due to regulatory concerns, particularly around data protection and AI governance as outlined in the EU’s AI Act and GDPR.
US-Centric Initial Release: The WhatsApp integration, for instance, is currently limited to users in the United States. This phased rollout approach is common for new AI technologies, allowing for controlled testing and refinement before wider release.
The Open-Source Advantage: Meta’s Vision for AI Democratization
Meta’s decision to make Llama 3 405B and its siblings open-source is more than just a technical choice—it’s a philosophical stance on the future of AI development. This approach offers several significant advantages and aligns with a broader vision for democratizing AI technology.
Meta’s Vision for Open AI
Mark Zuckerberg, in his letter about open-source AI, outlined several key points that underscore Meta’s commitment to this approach:
- Widespread Access: Open-source ensures that more people around the world have access to the benefits and opportunities of AI.
- Decentralization of Power: By making advanced AI models openly available, Meta aims to prevent the concentration of AI capabilities in the hands of a small few.
- Safety and Equitable Deployment: Open-source models can be deployed more evenly and safely across society, allowing for broader scrutiny and collaborative safety measures.
Impact on the AI Ecosystem
Meta’s open-source strategy with Llama models represents a bold bet on the power of collaborative, transparent AI development. While challenges remain, this approach has the potential to democratize AI technology, foster innovation, and push the entire field towards more open and accountable practices. As the AI community continues to work with and build upon Llama models, we’ll likely see the full impact of this open-source vision unfold in the coming years.
The Future of AI: Open vs. Closed Models
The release of Llama 3 405B marks a significant moment in the ongoing debate between open and closed AI models. As we look to the future, this divide is likely to shape the landscape of AI development and deployment.
Shifting Industry Dynamics
The impressive performance of Llama 3 405B, rivaling closed-source giants like GPT-4 and Claude 3.5 Sonnet, signals a potential shift in the industry. We’re seeing a narrowing gap between open and closed models, which could have far-reaching implications:
- Competitive Pressure: As open-source models like Llama approach or match the capabilities of closed models, companies relying on proprietary AI may face increased pressure to justify their closed approach.
- Collaborative Innovation: The open nature of Llama could accelerate the pace of AI innovation through collaborative efforts, potentially outpacing the development speed of closed models.
- Democratization of AI: Improved open-source models could lead to wider adoption of AI technologies across various industries, particularly benefiting smaller companies and developers with limited resources.
Conclusion
The release of Llama 3 405B and its siblings represents a significant milestone in the evolution of AI technology. By delivering open-source models that rival the performance of leading closed-source alternatives, Meta has not only showcased impressive technical achievements but also challenged the status quo of AI development.
As we look to the future, the line between open and closed AI models may continue to blur. The success of Llama models could inspire a new wave of open collaboration in AI research and development, potentially accelerating innovation across the field. However, challenges remain, particularly in areas of ethical deployment, regulatory compliance, and sustainable development practices.
Ultimately, the impact of Llama 3 405B extends far beyond its impressive benchmarks. It represents a bold step towards a more open, collaborative, and accessible AI future. As developers, researchers, and businesses continue to explore and build upon these models, we may well be witnessing the early stages of a fundamental shift in how AI technologies are developed, distributed, and deployed across the globe.
The AI race is far from over, but with Llama 3 405B, open-source AI has undoubtedly gained significant ground. The upcoming months and years will reveal whether this marks the beginning of a new, more open era in artificial intelligence, or if closed models will find ways to maintain their edge. Either way, the beneficiaries of this competition will be the users and developers who gain access to increasingly powerful AI tools and capabilities.
Leave a Reply
You must be logged in to post a comment.